“Data really powers everything that we do.”
– Jeff Weiner, CEO, LinkedIn
In this post, I will be focusing on creating AWS Data Catalogs based on CSV/XML/JSON files in S3 buckets and populating them in the redshift spectrum.
- Most of the time when bring external system data to Datalake, the data files comes in one of the popular formats, like CSV, XML or JSON.
- CSV is one of popular formats for data unloads from structural data where as XML and JSON is can handle be complex data structures for migrating data into lake.
We will be looking at how to crawl on various types of data formats and populate data catalogs. To achieve this we have various task lists to perform. These steps are almost the same for CSV/XML/JSON files. I will specify the additional steps for each file format if needed in relevant sections.
Step-2: Create Buckets and place files.
Step-3: Create Glue Catalog Database.
Step-4: Create and Run Crawler.
Step-5: Verify Table and Schema
Step-6: Integrate Glue Data Catalog into Redshift Spectrum
Step-1: Create IAM Role
Create new Glue Execution Role =>
choose AWS service => Choose Trusted entities (GLUE) from drop down => Next >
Add policiy:
1. AWS managed: AmazonS3FullAccess
2. AWS managed: AWSGlueServiceRole
3. Inline policy: name : kms-key(if kms encryption is enabled)
Json data for kms-key:
{
"Statement": [
{
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Effect": "Allow",
"Resource": "<<kms key arn>>"
}
],
"Version": "2012-10-17"
}Step-2: Create Buckets and place files.
In the real world, the data can be received in various ways to AWS S3 Buckets.
# Create Bucket "raw_retail_banking_accounts" bucket
There is a file test.csv in "Downloads/s3bucket" directory.
>>> cat Downloads/s3bucket/test.csv
id,name,age
1,Simon,35
2,Mathew,55
>>>aws --profile=dev-aws s3 sync Downloads/s3bucket s3://s3bucket/
upload: Downloads/s3bucket/test.csv to s3://s3bucket/test.csv
>>>aws --profile=dev-aws s3 ls Downloads/s3bucket s3://s3bucket/
2022-03-09 23:10:13 35 test.csv
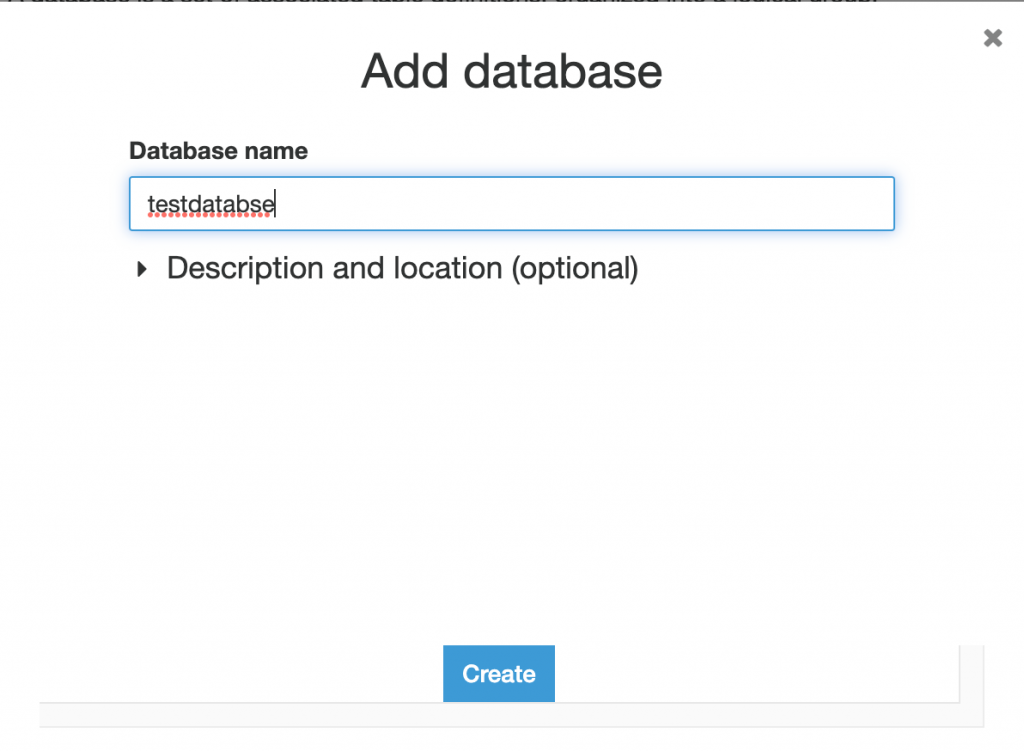
Step-3: Create Glue Catalog Database.
Please follow the carousel to see the steps to crate and verify the database in AWS Glue Catalog.

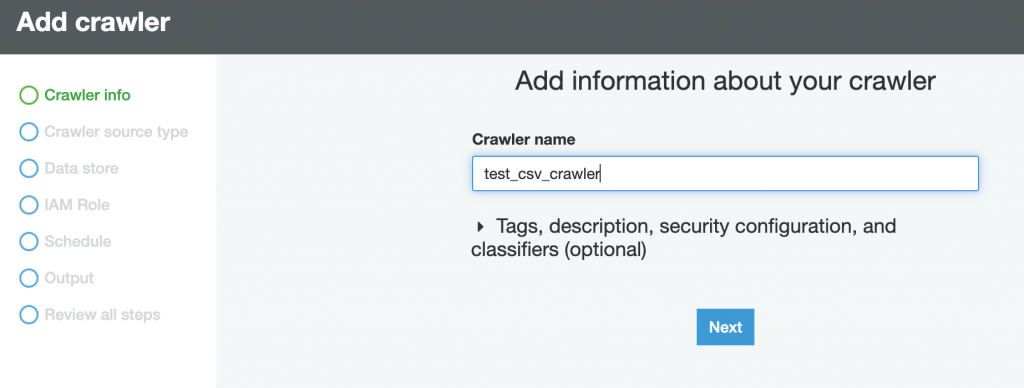
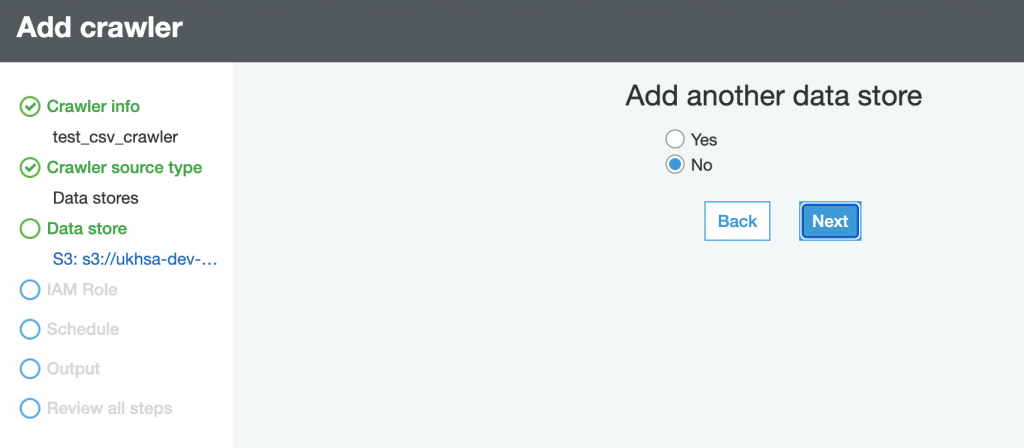
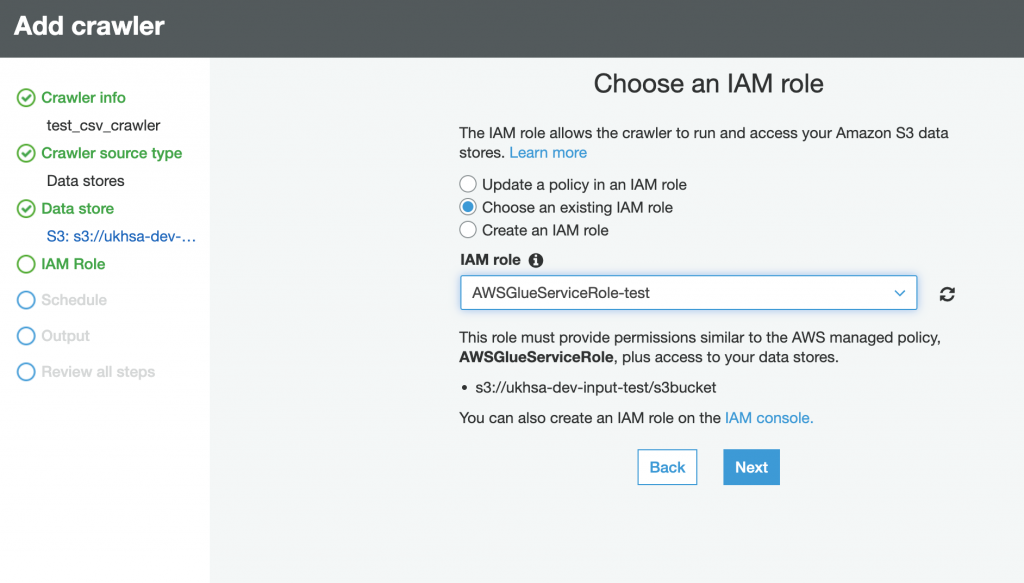
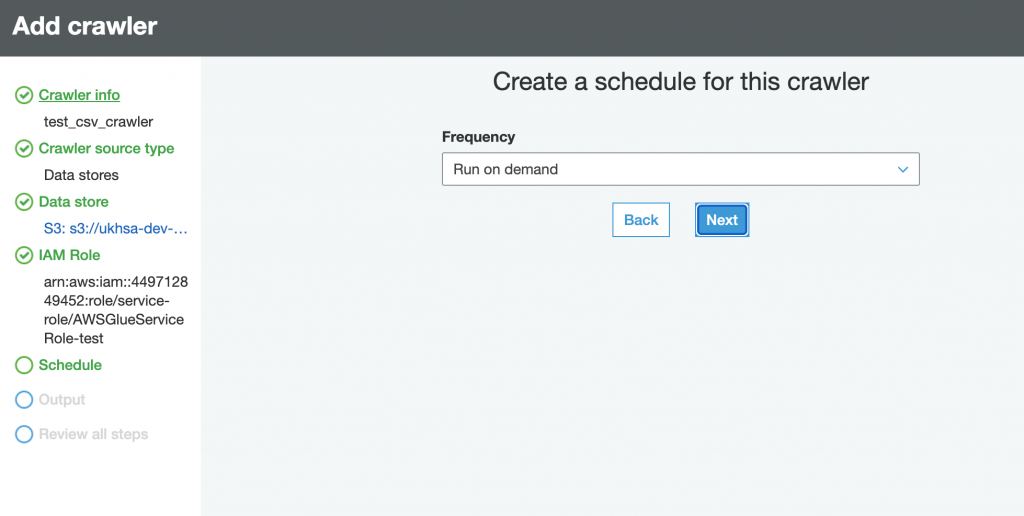
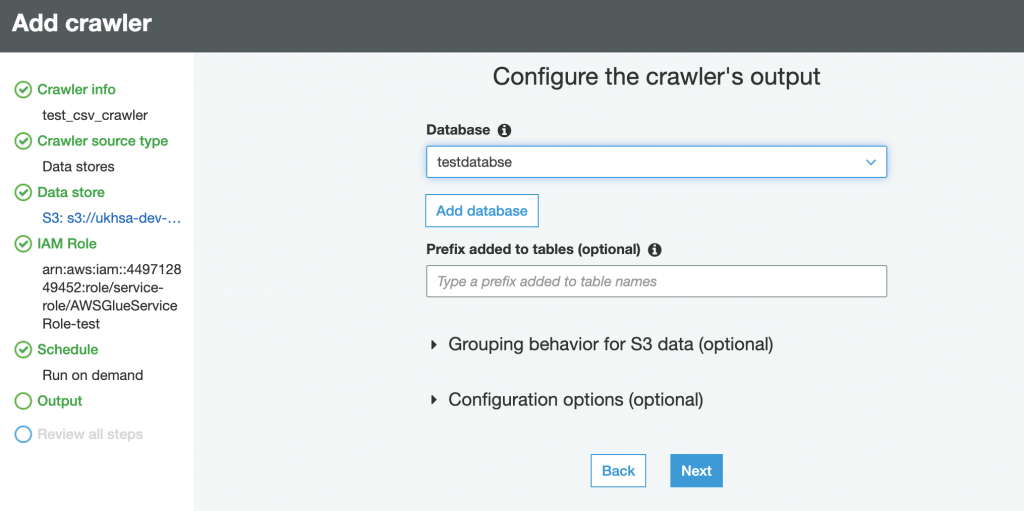
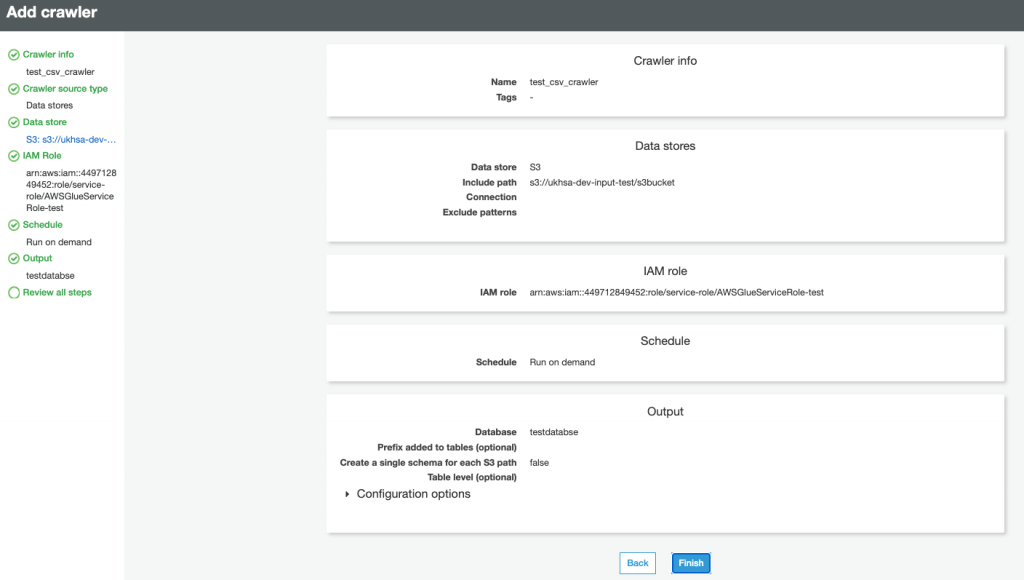
Step-4: Create and Run Crawler.
Please follow the carousel to see the steps to crate and verify the database in AWS Glue Crawler. The steps below do not cover all the features in Glue Crawler, rathe this is a typical step to create a crawler to crawl on CSV File located in S3.
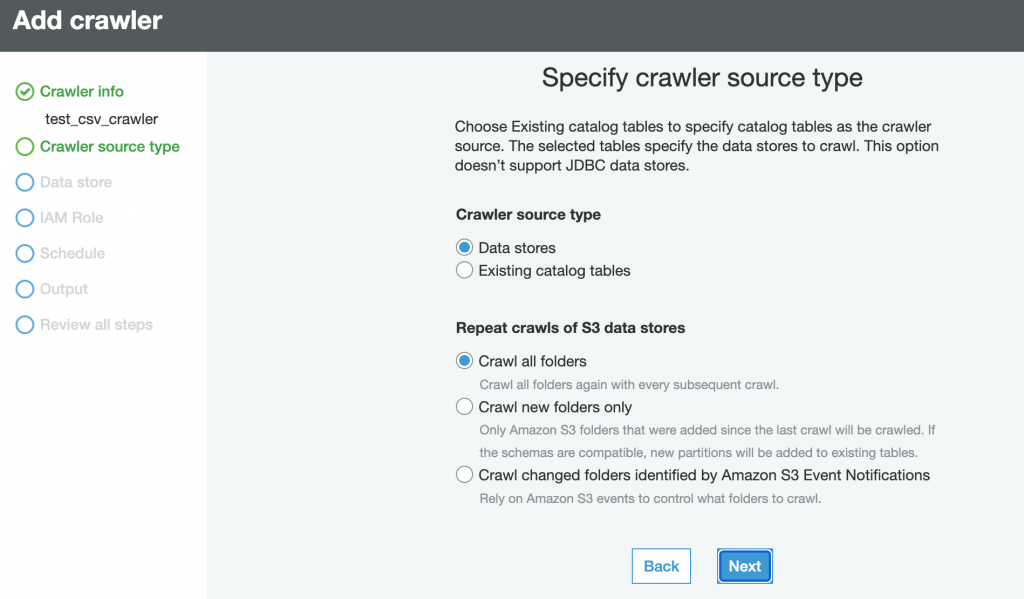
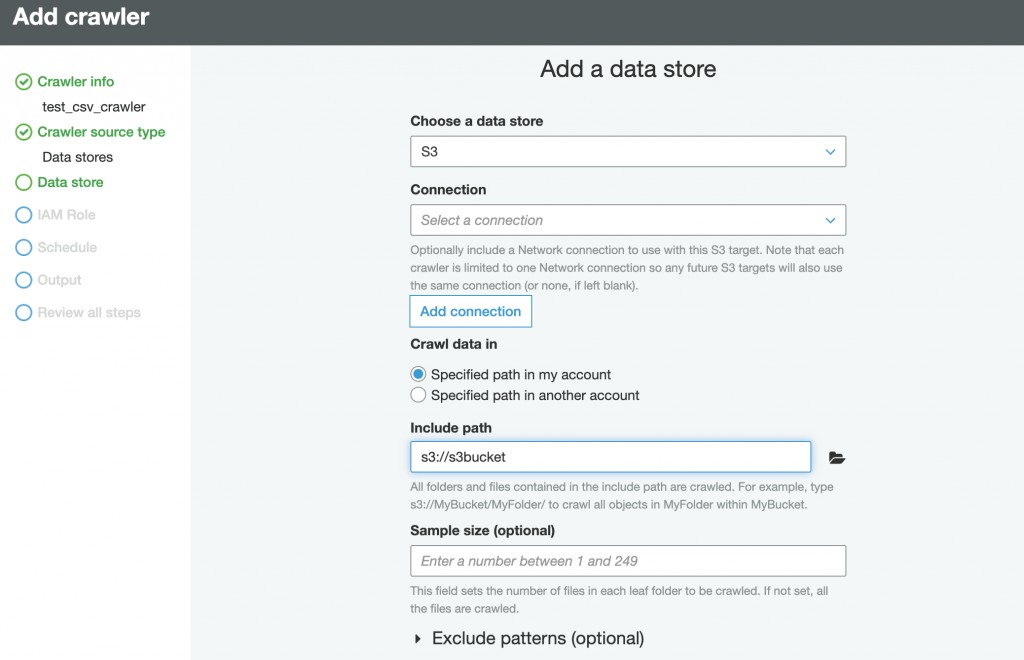

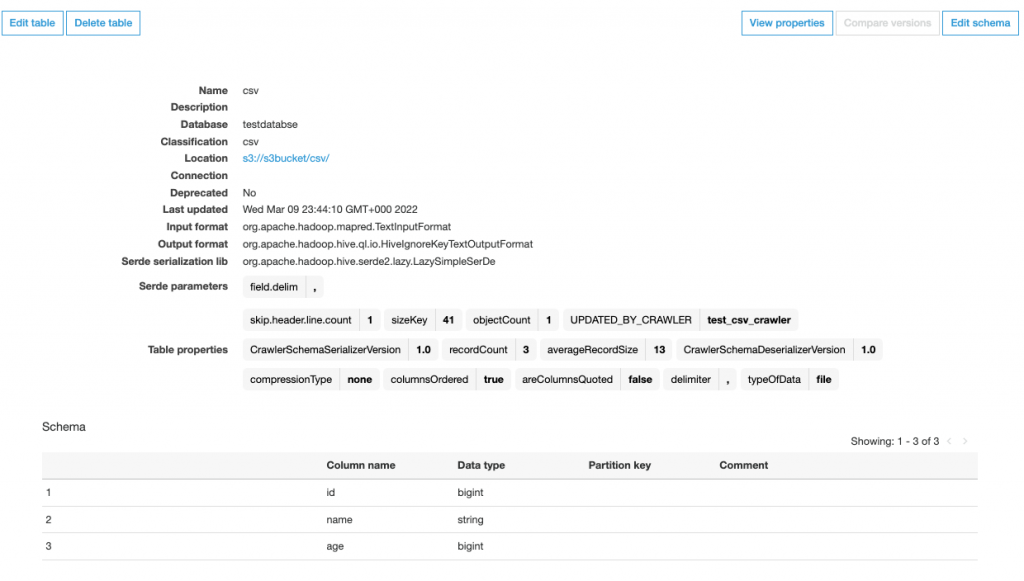
Step-5: Verify Table and Schema
After the crawler ran successfully, need to verify if the table is created/updated with the schema created as per the data present in the CSV file.



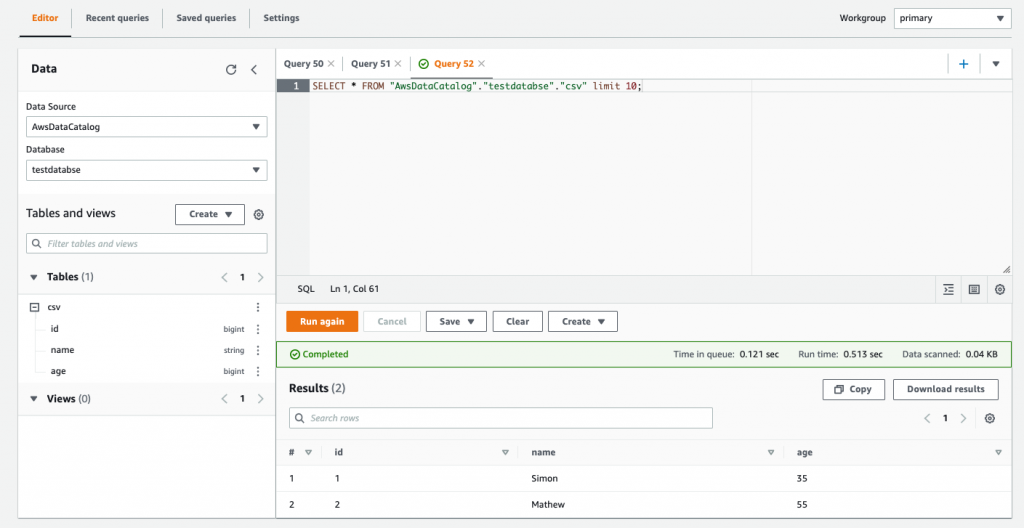
Step-6: Integrate Glue Data Catalog into Redshift Spectrum
#Create Exernale Schema "gluetablescheama" from Glue Data Catalog
# Glue database Name : testdatabase
# IAM_ROLE: IAM role to be created with glue,redshift and S3full access.
CREATE EXTERNAL SCHEMA IF NOT EXISTS gluetablescheama
FROM DATA CATALOG
DATABASE 'testdatabase'
REGION 'eu-west-2'
IAM_ROLE 'arn:aws:iam::<AWS account-id>:role/<role-name>'
CREATE EXTERNAL DATABASE IF NOT EXISTS
I have another post that has detailed steps to create user, group, and schema.